Search Bar
Every workspace has a Search Bar to navigate through it.

It can be triggered with shortcut Ctrl + K & ⌘k on Mac, or with Search button from sidebar. From here you can select from the options with the mouse or browse with the arrow keys.

Only Superadmins, Admins & Developers (not Operators) have access to this feature.
It can go to several pages:
Prefix keys
With a special prefix key, you can search accros:
- Completed runs (arguments, results) with with key
>. - Content of scripts, flows and apps with key
#(without Enterprise Edition, content search will only search among 10 scripts, 3 flows, 3 apps and 3 resources). - Logs with key
!.

Search accross runs with key
>.
Searching runs
You can search through completed runs by selecting the option on the search menu, or by prefixing your search with >.
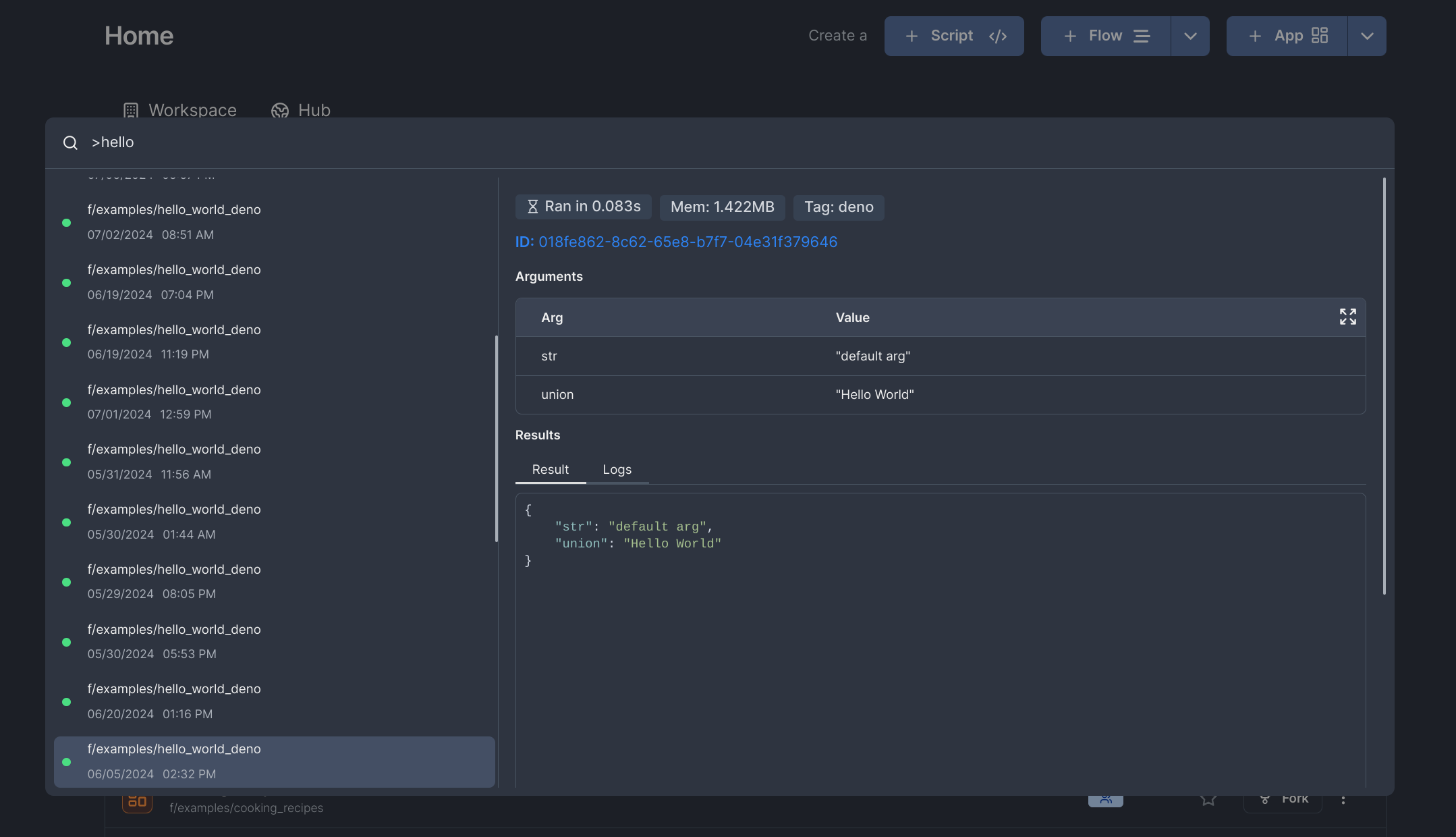
Queries are parsed by Tantivy's QueryParser, which lets you build relatively complex and useful queries. For example, you can try searching:
> script_path:u/user/searchable_flow AND success:false
to get the jobs corresponding to said path that also failed.
Learn more about the query syntax: Tantivy QueryParser docs
Searchable fields for jobs
The fields that are indexed and that you can use with the my_field:some_text syntax, :
| Filed name | Type |
|---|---|
| id | TEXT |
| parent_job | TEXT |
| created_by | TEXT |
| duration_ms | INT |
| success | BOOL |
| script_hash | TEXT |
| script_path | TEXT |
| args | TEXT |
| result | TEXT |
| logs | TEXT |
| deleted | BOOL |
| canceled | BOOL |
| canceled_by | TEXT |
| canceled_reason | TEXT |
| job_kind | TEXT |
| schedule_path | TEXT |
| permissioned_as | TEXT |
| is_flow_step | BOOL |
| language | TEXT |
| is_skipped | BOOL |
| TEXT | |
| visible_to_owner | BOOL |
| mem_peak | INT |
| tag | TEXT |
| created_at | DATE |
| started_at | DATE |
Content search
By using the # prefix, you can use windmill's Content Search and search through scripts, flows, and apps.
Searching logs
Searching through Windmill's service logs as well as audit logs is comming soon.
Setup
Setup using docker compose
On the Windmill's docker-compose.yml there is an example of how to setup the indexer container to enable full text search, just make sure to change replicas from 0 to 1.
# The indexer powers full-text job and log search, an EE feature.
windmill_indexer:
image: ${WM_IMAGE}
pull_policy: always
deploy:
replicas: 1 # set to 1 to enable full-text job and log search
restart: unless-stopped
expose:
- 8001
environment:
- PORT=8001
- DATABASE_URL=${DATABASE_URL}
- MODE=indexer
- TANTIVY_MAX_INDEXED_JOB_LOG_SIZE__MB=1 # job logs bigger than this will be truncated before indexing
- TANTIVY_S3_BACKUP_PERIOD__S=3600 # how often to backup the index into object storage
- TANTIVY_INDEX_WRITER_MEMORY_BUDGET__MB=100 # higher budget for higher indexing throughput
- TANTIVY_REFRESH_INDEX_PERIOD__S=300 #how often to start indexing new jobs
- TANTIVY_DOC_COMMIT_MAX_BATCH_SIZE=100000 #how many documents to batch in one commit
- TANTIVY_SHOW_MEMORY_EVERY=10000 #log memory usage and progress every so many documents indexed
depends_on:
db:
condition: service_healthy
volumes:
- windmill_index:/tmp/windmill/search
The indexer is in charge of both indexing new jobs and answering search queries. Because of this, we also need to redirect search requests to this container instead of the normal windmill server. This is what it looks like if you're using Caddy:
{$BASE_URL} {
bind {$ADDRESS}
reverse_proxy /ws/* http://lsp:3001
# reverse_proxy /ws_mp/* http://multiplayer:3002
reverse_proxy /api/srch/* http://windmill_indexer:8001
reverse_proxy /* http://windmill_server:8000
# tls /certs/cert.pem /certs/key.pem
}
Redirecting requests prefixed by /api/srch to port 8001 (same port as in the docker-compose.yml)
Setup using helm charts
Configuration
Environment variables
The index can be configured through a couple of environment variables.
| env var | default | description |
|---|---|---|
| TANTIVY_MAX_INDEXED_JOB_LOG_SIZE__MB | 1 | Job logs bigger than this will be truncated before indexing, This is to reduce the index size and to improve indexing performance. |
| TANTIVY_S3_BACKUP_PERIOD__S | 3600 | How often to backup the index into object storage |
| TANTIVY_INDEX_WRITER_MEMORY_BUDGET__MB | 100 | How much memory the writer can use before writing to disk. Increasing it can improve indexing throughput. |
| TANTIVY_DOC_COMMIT_MAX_BATCH_SIZE | 100000 | Every TANTIVY_REFRESH_INDEX_PERIOD__S, the indexer will commit the jobs written, making them searchable. This variable sets an amount of jobs after which to early-commit, to make the jobs searchable. This is mainly relevant for the first run (when running the whole completed_job table). Lower values can hurt indexing throughput. |
| TANTIVY_REFRESH_INDEX_PERIOD__S | 300 | Adding new jobs to the index. Jobs are only available to be searched after they are indexed and commited |
| TANTIVY_SHOW_MEMORY_EVERY | 10000 | Log memory usage and indexing progress every this many jobs |
Index persistence
There are two ways to make the index persistent (and avoid reindexing all jobs at every restart). The recommended way is to setup an object storage such as Amazon S3, and the index will automatically be backed up and pulled from there. This can be done by setting up S3/Azure for python cache and large logs.
It is also possible to store the index in a volume attached to the indexer container. The docker-compose.yml serves as an example of how to set it up (on /tmp/windmill/search).